![]()
Ace Databricks-Certified-Data-Engineer-Associate Certification with 102 Actual Questions
PASS Databricks Databricks-Certified-Data-Engineer-Associate EXAM WITH UPDATED DUMPS
NEW QUESTION # 21
Which of the following tools is used by Auto Loader process data incrementally?
- A. Spark Structured Streaming
- B. Checkpointing
- C. Unity Catalog
- D. Data Explorer
- E. Databricks SQL
Answer: A
Explanation:
Explanation
The Auto Loader process in Databricks is typically used in conjunction with Spark Structured Streaming to process data incrementally. Spark Structured Streaming is a real-time data processing framework that allows you to process data streams incrementally as new data arrives. The Auto Loader is a feature in Databricks that works with Structured Streaming to automatically detect and process new data files as they are added to a specified data source location. It allows for incremental data processing without the need for manual intervention.
How does Auto Loader track ingestion progress? As files are discovered, their metadata is persisted in a scalable key-value store (RocksDB) in the checkpoint location of your Auto Loader pipeline. This key-value store ensures that data is processed exactly once. In case of failures, Auto Loader can resume from where it left off by information stored in the checkpoint location and continue to provide exactly-once guarantees when writing data into Delta Lake. You don't need to maintain or manage any state yourself to achieve fault tolerance or exactly-once semantics.https://docs.databricks.com/ingestion/auto-loader/index.html
NEW QUESTION # 22
Which of the following is stored in the Databricks customer's cloud account?
- A. Repos
- B. Databricks web application
- C. Cluster management metadata
- D. Notebooks
- E. Data
Answer: E
NEW QUESTION # 23
Which of the following describes a benefit of creating an external table from Parquet rather than CSV when using a CREATE TABLE AS SELECT statement?
- A. Parquet files will become Delta tables
- B. Parquet files have the ability to be optimized
- C. Parquet files can be partitioned
- D. Parquet files have a well-defined schema
- E. CREATE TABLE AS SELECT statements cannot be used on files
Answer: D
Explanation:
Explanation
https://www.databricks.com/glossary/what-is-parquet#:~:text=Columnar%20storage%20like%20Apache%20Par Columnar storage like Apache Parquet is designed to bring efficiency compared to row-based files like CSV.
When querying, columnar storage you can skip over the non-relevant data very quickly. As a result, aggregation queries are less time-consuming compared to row-oriented databases.
NEW QUESTION # 24
A data engineer wants to create a new table containing the names of customers that live in France.
They have written the following command: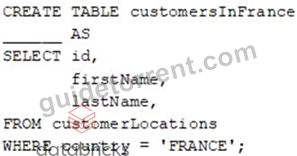
A senior data engineer mentions that it is organization policy to include a table property indicating that the new table includes personally identifiable information (PII).
Which of the following lines of code fills in the above blank to successfully complete the task?
- A. COMMENT "Contains PII"
- B. "COMMENT PII"
- C. There is no way to indicate whether a table contains PII.
- D. TBLPROPERTIES PII
- E. PII
Answer: A
Explanation:
Explanation
Ref:https://www.databricks.com/discover/pages/data-quality-management
CREATE TABLE my_table (id INT COMMENT 'Unique Identification Number', name STRING COMMENT 'PII', age INT COMMENT 'PII') TBLPROPERTIES ('contains_pii'=True) COMMENT 'Contains PII';
NEW QUESTION # 25
In which of the following scenarios should a data engineer use the MERGE INTO command instead of the INSERT INTO command?
- A. When the target table cannot contain duplicate records
- B. When the location of the data needs to be changed
- C. When the source is not a Delta table
- D. When the source table can be deleted
- E. When the target table is an external table
Answer: A
Explanation:
Explanation
With merge , you can avoid inserting the duplicate records. The dataset containing the new logs needs to be deduplicated within itself. By the SQL semantics of merge, it matches and deduplicates the new data with the existing data in the table, but if there is duplicate data within the new dataset, it is inserted.https://docs.databricks.com/en/delta/merge.html#:~:text=With%20merge%20%2C%20you%20can%20a
NEW QUESTION # 26
A data engineer wants to create a data entity from a couple of tables. The data entity must be used by other data engineers in other sessions. It also must be saved to a physical location.
Which of the following data entities should the data engineer create?
- A. Temporary view
- B. Database
- C. Function
- D. Table
- E. View
Answer: D
Explanation:
1: A table is a data entity that is stored in a physical location and can be accessed by other data engineers in other sessions. A table can be created from one or more tables using the CREATE TABLE or CREATE TABLE AS SELECT commands. A table can also be registered from an existing DataFrame using the spark.catalog.createTable method. A table can be queried using SQL or DataFrame APIs. A table can also be updated, deleted, or appended using the MERGE INTO command or the DeltaTable API. Reference:
Create a table
Create a table from a query result
Register a table from a DataFrame
[Query a table]
[Update, delete, or merge into a table]
NEW QUESTION # 27
A data engineer wants to schedule their Databricks SQL dashboard to refresh every hour, but they only want the associated SQL endpoint to be running when It is necessary. The dashboard has multiple queries on multiple datasets associated with it. The data that feeds the dashboard is automatically processed using a Databricks Job.
Which approach can the data engineer use to minimize the total running time of the SQL endpoint used in the refresh schedule of their dashboard?
- A. 0 They can ensure the dashboard's SQL endpoint matches each of the queries' SQL endpoints.
- B. O They can reduce the cluster size of the SQL endpoint.
- C. Q They can turn on the Auto Stop feature for the SQL endpoint.
- D. O They can set up the dashboard's SQL endpoint to be serverless.
Answer: C
Explanation:
To minimize the total running time of the SQL endpoint used in the refresh schedule of a dashboard in Databricks, the most effective approach is to utilize the Auto Stop feature. This feature allows the SQL endpoint to automatically stop after a period of inactivity, ensuring that it only runs when necessary, such as during the dashboard refresh or when actively queried. This minimizes resource usage and associated costs by ensuring the SQL endpoint is not running idle outside of these operations.
Reference:
Databricks documentation on SQL endpoints: SQL Endpoints in Databricks
NEW QUESTION # 28
Which of the following approaches should be used to send the Databricks Job owner an email in the case that the Job fails?
- A. Setting up an Alert in the Job page
- B. MLflow Model Registry Webhooks
- C. There is no way to notify the Job owner in the case of Job failure
- D. Setting up an Alert in the Notebook
- E. Manually programming in an alert system in each cell of the Notebook
Answer: A
Explanation:
To send the Databricks Job owner an email in the case that the Job fails, the best approach is to set up an Alert in the Job page. This way, the Job owner can configure the email address and the notification type for the Job failure event. The other options are either not feasible, not reliable, or not relevant for this task. Manually programming an alert system in each cell of the Notebook is tedious and error-prone. Setting up an Alert in the Notebook is not possible, as Alerts are only available for Jobs and Clusters. There is a way to notify the Job owner in the case of Job failure, so option D is incorrect. MLflow Model Registry Webhooks are used for model lifecycle events, not Job events, so option E is not applicable. References:
* Add email and system notifications for job events
* Alerts
* MLflow Model Registry Webhooks
NEW QUESTION # 29
A data engineer that is new to using Python needs to create a Python function to add two integers together and return the sum?
Which of the following code blocks can the data engineer use to complete this task?
- A.

- B.

- C.

- D.

- E.

Answer: D
Explanation:
https://www.w3schools.com/python/python_functions.asp
https://www.geeksforgeeks.org/python-functions/
NEW QUESTION # 30
Which of the following commands can be used to write data into a Delta table while avoiding the writing of duplicate records?
- A. MERGE
- B. DROP
- C. APPEND
- D. INSERT
- E. IGNORE
Answer: A
NEW QUESTION # 31
A data engineer wants to create a new table containing the names of customers that live in France.
They have written the following command: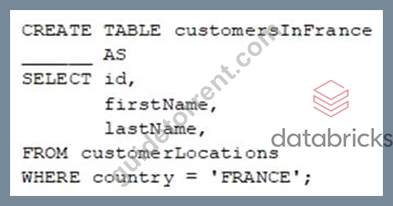
A senior data engineer mentions that it is organization policy to include a table property indicating that the new table includes personally identifiable information (PII).
Which of the following lines of code fills in the above blank to successfully complete the task?
- A. COMMENT "Contains PII"
- B. "COMMENT PII"
- C. There is no way to indicate whether a table contains PII.
- D. TBLPROPERTIES PII
- E. PII
Answer: A
Explanation:
In Databricks, when creating a table, you can add a comment to columns or the entire table to provide more information about the data it contains. In this case, since it's organization policy to indicate that the new table includes personally identifiable information (PII), option D is correct. The line of code would be added after defining the table structure and before closing with a semicolon. References: Data Engineer Associate Exam Guide, CREATE TABLE USING (Databricks SQL)
NEW QUESTION # 32
Which of the following benefits of using the Databricks Lakehouse Platform is provided by Delta Lake?
- A. The ability to distribute complex data operations
- B. The ability to collaborate in real time on a single notebook
- C. The ability to manipulate the same data using a variety of languages
- D. The ability to set up alerts for query failures
- E. The ability to support batch and streaming workloads
Answer: E
Explanation:
Explanation
Delta Lake is a key component of the Databricks Lakehouse Platform that provides several benefits, and one of the most significant benefits is its ability to support both batch and streaming workloads seamlessly. Delta Lake allows you to process and analyze data in real-time (streaming) as well as in batch, making it a versatile choice for various data processing needs. While the other options may be benefits or capabilities of Databricks or the Lakehouse Platform in general, they are not specifically associated with Delta Lake.
NEW QUESTION # 33
A data engineer has a Job with multiple tasks that runs nightly. Each of the tasks runs slowly because the clusters take a long time to start.
Which of the following actions can the data engineer perform to improve the start up time for the clusters used for the Job?
- A. They can configure the clusters to be single-node
- B. They can use endpoints available in Databricks SQL
- C. They can configure the clusters to autoscale for larger data sizes
- D. They can use jobs clusters instead of all-purpose clusters
- E. They can use clusters that are from a cluster pool
Answer: E
Explanation:
The best action that the data engineer can perform to improve the start up time for the clusters used for the Job is to use clusters that are from a cluster pool. A cluster pool is a set of idle clusters that can be used by jobs or interactive sessions. By using a cluster pool, the data engineer can avoid the cluster creation time and reduce the latency of the tasks. Cluster pools also offer cost savings and resource efficiency, as they can be shared by multiple users and jobs.
Option A is not relevant, as endpoints available in Databricks SQL are used for creating and managing SQL analytics workloads, not for improving cluster start up time.
Option B is not correct, as jobs clusters and all-purpose clusters have similar start up times. Jobs clusters are clusters that are dedicated to run a single job and are terminated when the job is completed. All-purpose clusters are clusters that can be used for multiple purposes, such as interactive sessions, notebooks, or multiple jobs. Both types of clusters can benefit from using a cluster pool.
Option C is not advisable, as configuring the clusters to be single-node will reduce the parallelism and performance of the tasks. Single-node clusters are clusters that have only one worker node and are typically used for testing or development purposes. They are not suitable for running production jobs that require high scalability and fault tolerance.
Option E is not helpful, as configuring the clusters to autoscale for larger data sizes will not affect the start up time of the clusters. Autoscaling is a feature that allows clusters to dynamically adjust the number of worker nodes based on the workload. It can help optimize the resource utilization and cost efficiency of the clusters, but it does not speed up the cluster creation process.
Reference:
Cluster Pools
Jobs
Clusters
[Databricks Data Engineer Professional Exam Guide]
NEW QUESTION # 34
Which of the following benefits of using the Databricks Lakehouse Platform is provided by Delta Lake?
- A. The ability to distribute complex data operations
- B. The ability to collaborate in real time on a single notebook
- C. The ability to manipulate the same data using a variety of languages
- D. The ability to set up alerts for query failures
- E. The ability to support batch and streaming workloads
Answer: E
NEW QUESTION # 35
Which of the following describes the storage organization of a Delta table?
- A. Delta tables are stored in a collection of files that contain data, history, metadata, and other attributes.
- B. Delta tables are stored in a single file that contains data, history, metadata, and other attributes.
- C. Delta tables store their data in a single file and all metadata in a collection of files in a separate location.
- D. Delta tables are stored in a collection of files that contain only the data stored within the table.
- E. Delta tables are stored in a single file that contains only the data stored within the table.
Answer: A
Explanation:
Explanation
Delta tables store data in a structured manner using Parquet files, and they also maintain metadata and transaction logs in separate directories. This organization allows for versioning, transactional capabilities, and metadata tracking in Delta Lake. Thank you for pointing out the error, and I appreciate your understanding.
NEW QUESTION # 36
A single Job runs two notebooks as two separate tasks. A data engineer has noticed that one of the notebooks is running slowly in the Job's current run. The data engineer asks a tech lead for help in identifying why this might be the case.
Which of the following approaches can the tech lead use to identify why the notebook is running slowly as part of the Job?
- A. There is no way to determine why a Job task is running slowly.
- B. They can navigate to the Tasks tab in the Jobs UI and click on the active run to review the processing notebook.
- C. They can navigate to the Runs tab in the Jobs UI and click on the active run to review the processing notebook.
- D. They can navigate to the Runs tab in the Jobs UI to immediately review the processing notebook.
- E. They can navigate to the Tasks tab in the Jobs UI to immediately review the processing notebook.
Answer: B
Explanation:
The Tasks tab in the Jobs UI shows the list of tasks that are part of a job, and allows the user to view the details of each task, such as the notebook path, the cluster configuration, the run status, and the duration. By clicking on the active run of a task, the user can access the Spark UI, the notebook output, and the logs of the task. These can help the user to identify the performance bottlenecks and errors in the task. The Runs tab in the Jobs UI only shows the summary of the job runs, such as the start time, the end time, the trigger, and the status. It does not provide the details of the individual tasks within a job run. Reference: Jobs UI, Monitor running jobs with a Job Run dashboard, How to optimize jobs performance
NEW QUESTION # 37
Which file format is used for storing Delta Lake Table?
- A. SV
- B. Delta
- C. Parquet
- D. JSON
Answer: C
Explanation:
Delta Lake tables use the Parquet format as their underlying storage format. Delta Lake enhances Parquet by adding a transaction log that keeps track of all the operations performed on the table. This allows features like ACID transactions, scalable metadata handling, and schema enforcement, making it an ideal choice for big data processing and management in environments like Databricks.
Reference:
Databricks documentation on Delta Lake: Delta Lake Overview
NEW QUESTION # 38
Which of the following can be used to simplify and unify siloed data architectures that are specialized for specific use cases?
- A. Data lakehouse
- B. Data lake
- C. None of these
- D. All of these
- E. Data warehouse
Answer: A
Explanation:
A data lakehouse is a new paradigm that can be used to simplify and unify siloed data architectures that are specialized for specific use cases. A data lakehouse combines the best of both data lakes and data warehouses, providing a single platform that supports diverse data types, open standards, low-cost storage, high-performance queries, ACID transactions, schema enforcement, and governance. A data lakehouse enables data engineers to build reliable and scalable data pipelines that can serve various downstream applications and users, such as data science, machine learning, analytics, and reporting. A data lakehouse leverages the power of Delta Lake, a storage layer that brings reliability and performance to data lakes. References: What is a data lakehouse?, Delta Lake, Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics
NEW QUESTION # 39
......
Databricks Certified Data Engineer Associate certification is designed to help professionals stay up-to-date with the latest data engineering trends and technologies. Databricks Certified Data Engineer Associate Exam certification exam is regularly updated to ensure that it reflects the latest developments in the field of data engineering. By earning this certification, professionals can demonstrate their commitment to professional development and their dedication to staying current in their field.
Databricks-Certified-Data-Engineer-Associate Questions PDF [2024] Use Valid New dump to Clear Exam: https://www.guidetorrent.com/Databricks-Certified-Data-Engineer-Associate-pdf-free-download.html
Passing Databricks Databricks-Certified-Data-Engineer-Associate Exam Using 2024 Practice Tests: https://drive.google.com/open?id=1Ddg8soBByGo3rPhDcD0_HOknsvXwjb8V